Dataset actieparameters
Dataset actieparameters
In dit hoofdstuk worden de parameters besproken welke in een aantal dataset taakacties voorkomen.
Filteren
Hier kunt u de dataregels uit de doel dataset filteren.
Voorbeeld
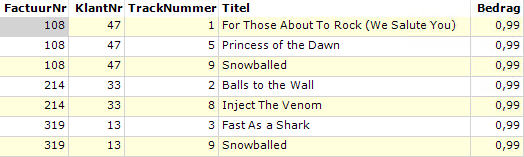
Stel de bron dataset heeft de volgende inhoud:

Deze dataset heeft 4 dataregels met 5 kolommen, gevuld met gegevens van verkochte muzieknummers.
Stel u bent alleen geïnteresseerd in InvoiceId nummer 1 en muzieknummers waarin het woord "wild" voorkomt.
We kunnen dit hier aangeven door de volgende twee filters aan te maken:
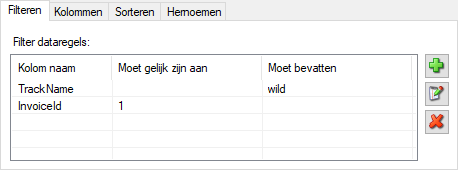
De actie zal deze filter toepassen en de dataregels, die hieraan niet voldoen, uit de dataset verwijderen, met de volgende dataset als resultaat:

Het eindresultaat is nu een dataset met 1 dataregel, welke de actie zal gebruiken voor de doel dataset.
NB: De inhoud van het geheugenveld welke de bron dataset voor deze actie aanlevert, zal niet gewijzigd worden. Het verwijderen van kolommen en regels gebeurt dus alleen binnen deze actie.
U kunt één of meerdere dataregelfilters aanmaken. Hiervoor zijn de volgende knoppen beschikbaar:
|
Pictogram |
Betekenis |
|
|
Toevoegen nieuwe dataregelfilter |
|
|
Wijzigen dataregelfilter |
|
|
Verwijder dataregelfilter |



Venster voor aanmaken/wijzigen filter:
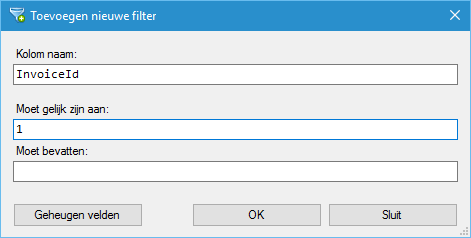
NB: De waarden die u hier invoert zijn case insensitive.
Kolommen
Op dit tabblad geeft u aan welke kolommen moeten worden opgenomen in de doel dataset.
Voorbeeld
Stel de doel dataset heeft in eerste instantie de volgende inhoud:
Deze dataset heeft 4 dataregels met 5 kolommen, gevuld met gegevens van verkochte muzieknummers.
Stel u bent alleen geïnteresseerd in de waardes van uit de kolommen InvoiceId, CustomerId en TrackName.
We kunnen dit hier aangeven door de gewenste kolomnamen in het tabblad Kolommen op te geven, gescheiden door een puntkomma (;):
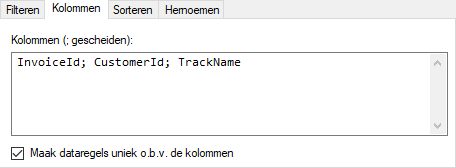
Het resultaat van het opgeven van deze kolomnamen zal er dan als volgt uit zien:
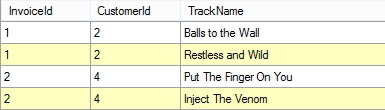
NB: In de doel dataset worden de kolommen in dezelfde volgorde opgenomen als u in dit scherm aangeeft.
NB: Indien u ook de parameter Maak dataregels uniek o.b.v. de kolommen gebruikt, houdt u er dan rekening mee dat u dan alleen kunt filteren op de inhoud van de resulterende dataset voortkomend uit die parameter instelling. M.a.w. indien u bij de parameter Maak dataregels uniek o.b.v. de kolommen bijvoorbeeld heeft aangegeven dat u alleen de kolommen TrackName en LineAmount wilt overhouden, dan kunt u hier niet meer filteren op de kolom InvoiceId, aangezien deze kolom dan niet meer in de dataset aanwezig is.
NB: De optie Maak dataregels uniek o.b.v. de kolommen zorgt ervoor dat regels in de resulterende dataset uniek worden gemaakt. M.a.w. regels met exact dezelfde inhoud, zullen slechts één keer in de resulterende dataset worden vermeld.
Sorteren
Op dit tabblad kunt u aangeven hoe de sortering van de in de doel dataset opgenomen kolommen moet gebeuren.
Indien op een kolom wilt sorteren, dient u de kolomnaam op te geven. U kunt hier optioneel aangeven wat de sorteervolgorde is:
|
asc |
Oplopend (in het Engels: ascending) sorteren |
|
desc |
Aflopend (in het Engels: descending) sorteren |
Indien u geen sorteervolgorde opgeeft, zal standaard oplopend (asc) worden gesorteerd. De sorteervolgorde dient, gescheiden door een spatie, achter de kolomnaam te staan.
Indien u op meerdere kolomnamen wilt sorteren, dient u deze in de gewenste volgorde op te geven, gescheiden door een komma.
Voorbeeld 1
Stel de doel dataset heeft in eerste instantie de volgende inhoud:
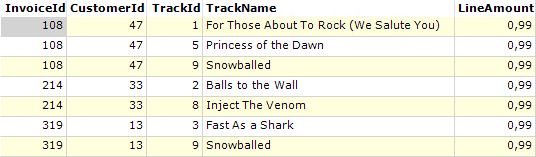
Deze dataset heeft 7 dataregels met 5 kolommen, gevuld met gegevens van verkochte muzieknummers.
Stel u wilt sorteren op TrackName.
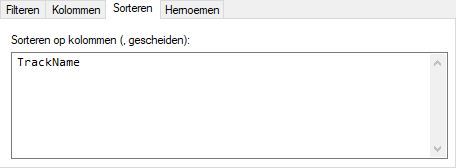
We kunnen dit hier aangeven door de kolomnaam in het tabblad Sorteren op te geven:
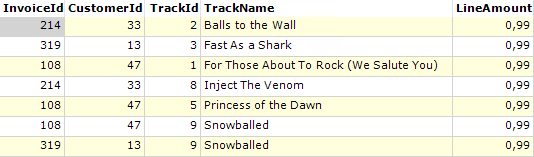
Het resultaat van deze sortering is dan als volgt:
Voorbeeld 2 - aflopend sorteren
Stel de doel dataset heeft in eerste instantie de volgende inhoud:
Stel u wilt aflopend (van z naar a) sorteren op TrackName.
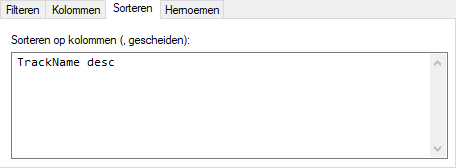
We kunnen dit hier aangeven door de kolomnaam in het tabblad Sorteren op te geven:
Het resultaat van deze sortering is dan als volgt:
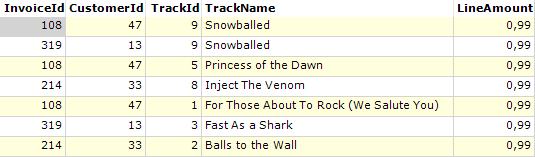
Voorbeeld 3 - sorteren op meerdere kolommen
Stel de doel dataset heeft in eerste instantie de volgende inhoud:
Stel u wilt aflopend (van z naar a) sorteren op TrackName.
We kunnen dit hier aangeven door de kolomnaam in het tabblad Sorteren op te geven:
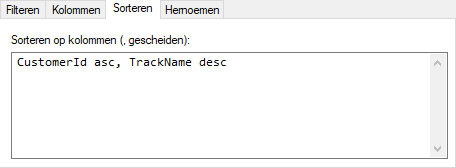
Het resultaat van deze sortering is dan een dataset met de volgende inhoud:
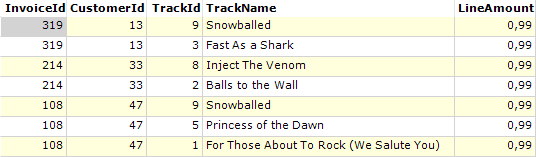
Hernoemen
In dit tabblad kunt u de kolommen uit de doel dataset hernoemen.
Voor het hernoeming bestaat uit 3 onderdelen, die achter elkaar worden geplaatst:
- de oorspronkelijke kolomnaam
- een 'gelijk aan' teken (=)
- de nieuwe kolomnaam
Voorbeeld
Stel de bron dataset heeft de volgende inhoud:
Stel u wilt alle kolommen hernoemen. U kunt dit hier aangeven door het volgende in te vullen:
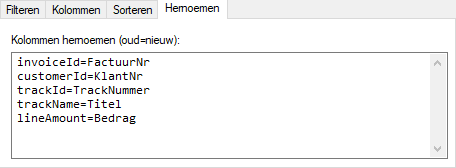
Het eindresultaat is nu een dataset met hernoemde kolomkoppen:
- Het is niet noodzakelijk om alle kolommen te hernoemen. Indien u een kolomnaam ongewijzigd wilt laten, dient u deze kolomnaam niet op te nemen in de hernoemlijst.
- Indien u kolomnamen opgeeft die niet in de doel dataset aanwezig zijn, resulteert dit niet in een foutmelding.