Dataset Lus
Deze actie wordt gebruikt om het begin van een lus aan te geven. Deze lus doorloopt de dataregels in een dataset. De acties binnen deze lus worden herhaaldelijk uitgevoerd; het aantal keren is gelijk aan het aantal dataregels in de dataset.
De door deze actie gebruikte dataset wordt aangeboden via een dataset geheugenveld. Dit dataset geheugenveld dient hiervoor eerst gevuld te worden, bijvoorbeeld door de actie Haal dataset met SQL query.
Voorbeeld
Stel u wilt een e-mail sturen naar alle klanten. Daarvoor heeft u onderstaande acties aangemaakt in de taak:
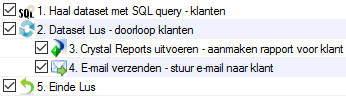
In stap 1 wordt middels de actie Haal dataset met SQL query een dataset geheugenveld gevuld met (bijvoorbeeld) 5 klanten.
In stap 2 staat deze actie (Dataset Lus). Dit is het begin van de lus. In deze actie wordt de bij stap 1 gevulde dataset geheugenveld aangewezen als bron voor de lus.
Aangezien de dataset uit 5 dataregels bestaat (want: de query leverde 5 klanten records op), zal de lus 5x worden doorlopen. De acties binnen deze lus (= acties in stap 3 en 4) worden dus 5x uitgevoerd.
Beschrijving parameters
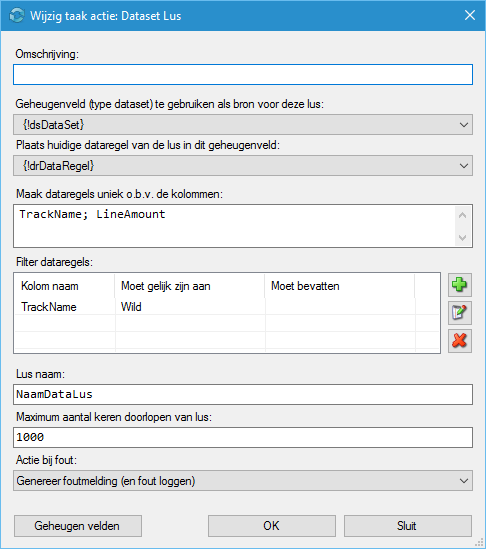
Omschrijving (optioneel)
Uitleg voor deze parameter vind u hier.
Geheugenveld (type dataset) te gebruiken als bron voor deze lus (verplicht)/Plaats huidige dataregel van de lus in dit geheugenveld (optioneel)
Bij Geheugenveld te gebruiken als bron voor deze lus dient u een dataset geheugenveld te kiezen welke als bron zal worden gebruikt voor de lus.
Bij Plaats huidige dataregel van de lus in dit geheugenveld kunt u een dataregel geheugenveld kiezen welke gevuld zal worden met de huidige dataregel uit de dataset.
Voorbeeld
Stel de dataset geheugenveld bevat 3 dataregels (met 1 kolom: "TrackName"):
"Fast As a Shark"
"Breaking The Rules"
"Spellbound"
Dit betekent dat de lus 3x wordt doorlopen.
Voor elke dataregel zal een dataregel geheugenveld worden gevuld, indien u die heeft opgegeven bij de parameter Doel geheugenveld voor dataregel.
De 1e keer dat de lus wordt doorlopen, zal de dataregel geheugenvel worden gevuld met de 1e dataregel uit de bron dataset:
"Fast As a Shark"
De 2de keer dat de lus wordt doorlopen, zal de dataregel geheugenveld worden gevuld met de 2de dataregel uit de bron dataset:
"Breaking The Rules"
De 3de keer dat de lus wordt doorlopen, zal de dataregel geheugenveld worden gevuld met de 3de dataregel uit de bron dataset:
"Spellbound"
Bij elke iteratie (= elke keer dat een lus wordt doorlopen) zal de huidige positie in de lijst dus opschuiven naar het volgende item. De huidige positie wordt ook wel een "cursor" genoemd.
Maak dataregels uniek o.b.v. de kolommen
Een dataset bevat één of meer kolommen. Indien een dataset meer kolommen bevat dan u nodig heeft dan kunt u hier aangeven welke kolommen u nodig heeft en bovendien de dan resulterende dataregels ontdubbelen.
Voorbeeld
Stel de bron dataset heeft de volgende inhoud:

Deze dataset heeft 3 dataregels met 5 kolommen, gevuld met gegevens van verkochte muzieknummers.
Stel u bent alleen geïnteresseerd in de naam en het bedrag van elk nummer. Indien het bedrag van een nummer gelijk is, dan wilt u dit nummer maar eenmaal terug zien.
We kunnen deze wens bij deze parameter aangeven door het volgende in te voeren:
TrackName ; LineAmount
In eerste instantie zal de actie de hier niet opgegeven kolommen verwijderen uit de dataset:

Daarna zal de actie de dubbele dataregels verwijderen uit de dataset:
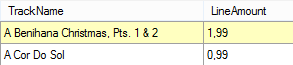
Het eindresultaat is nu een dataset met 2 dataregels en 2 kolommen, welke de actie zal gebruiken voor de lus. Dit betekent dus dat de lus nu niet 3x, maar 2x wordt doorlopen.
NB: De inhoud van het geheugenveld welke de bron dataset voor deze actie aanlevert, zal niet gewijzigd worden. Het verwijderen van kolommen en regels gebeurt dus alleen binnen deze actie.
U kunt een of meerdere kolomnamen invoeren, gescheiden door een puntkomma. Het is niet perse nodig om rondom de puntkomma een spatie toe te voegen, alhoewel dat wel de leesbaarheid vergroot.
Filter dataregels
Hier kunt u de dataregels in de opgegeven bron dataset filteren.
Voorbeeld
Stel de bron dataset heeft de volgende inhoud:

Deze dataset heeft 4 dataregels met 5 kolommen, gevuld met gegevens van verkochte muzieknummers.
Stel u bent alleen geïnteresseerd in InvoiceId nummer 1 en muzieknummers waarin het woord "wild" voorkomt.
We kunnen dit hier aangeven door de volgende twee filters aan te maken:

De actie zal deze filter toepassen en de dataregels, die hieraan niet voldoen, uit de dataset verwijderen, met de volgende dataset als resultaat:

Het eindresultaat is nu een dataset met 1 dataregel, welke de actie zal gebruiken voor de lus. Dit betekent dus dat de lus nu niet 4x, maar 1x wordt doorlopen.
NB: De inhoud van het geheugenveld welke de bron dataset voor deze actie aanlevert, zal niet gewijzigd worden. Het verwijderen van kolommen en regels gebeurt dus alleen binnen deze actie.
NB: Indien u ook de parameter Maak dataregels uniek o.b.v. de kolommen gebruikt, houdt u er dan rekening mee dat u dan alleen kunt filteren op de inhoud van de resulterende dataset voortkomend uit die parameter instelling. M.a.w. indien u bij de parameter Maak dataregels uniek o.b.v. de kolommen bijvoorbeeld heeft aangegeven dat u alleen de kolommen TrackName en LineAmount wilt overhouden, dan kunt u hier niet meer filteren op de kolom InvoiceId, aangezien deze kolom dan niet meer in de dataset aanwezig is.
U kunt één of meerdere dataregelfilters aanmaken. Hiervoor zijn de volgende knoppen beschikbaar:
|
Pictogram |
Betekenis |
|
|
Toevoegen nieuwe dataregelfilter |
|
|
Wijzigen dataregelfilter |
|
|
Verwijder dataregelfilter |



Venster voor aanmaken/wijzigen filter:
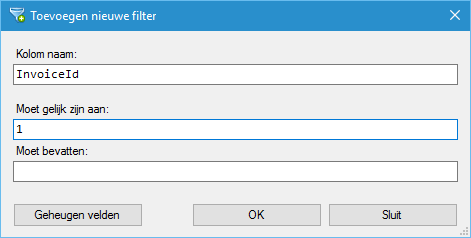
NB: De waarden die u hier invoert zijn case insensitive.
Lus naam
U kunt deze lus een naam geven. Indien de lus een naam heeft kunnen andere acties deze lus direct aanwijzen. Voor praktische voorbeelden hiervan verwijs ik u naar de acties Verlaat Lus en Vervolg Lus.
Maximum aantal lus iteraties
In BPM Server zit er altijd een beperking op het maximum aantal lus-iteraties. Anders gezegd: het aantal keren dat een lus kan worden doorlopen is niet onbeperkt. Dit is om te voorkomen dat de lus oneindig wordt vervolgd.
Indien u hier niets invoert geldt de standaard waarde welke u kunt instellen in de instellingen.
Indien het aantal lus-iteraties het ingestelde maximum heeft bereikt zal de lus worden verlaten en zal dit als waarschuwing in het taaklog worden geregistreerd.
Actie bij fout
Uitleg voor deze parameter vind u hier.