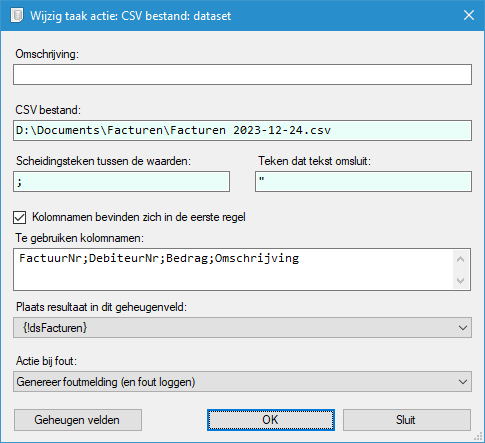
CSV bestand: dataset
Met deze actie kunt u een dataset ophalen o.b.v. de inhoud van een CSV-bestand. De resulterende dataset zal in een geheugenveld worden gezet, waarna deze in volgende acties van de taak gebruikt kan worden.
Hieronder ziet u een voorbeeld van de inhoud van een CSV-bestand:
FactuurNr;DebiteurNr;Bedrag;Omschrijving
20134344;1401;1190.00;"Houten ledikant; 2 meter"
20135487;1412;224.95;"Lederen bankstel; 3 zits"
In dit voorbeeld ziet u het volgende:
- De 1ste regel bevat de 4 kolomnamen van de velden: FactuurNr, DebiteurNr, Bedrag en Omschrijving.
- De 2de en 3de regel bevatten de waarden.
- De waarden worden hier gescheiden door een puntkomma.
- Er wordt een aanhalingsteken gebruikt voor het omsluiten van teksten (bij het Omschrijving-veld). Het omsluiten van teksten met een bepaald teken (= meestal een aanhalingsteken) is vooral van belang indien men verwacht dat de waarde (in bovenstaande voorbeeld Omschrijving) het scheidingsteken kan bevatten (in dit geval de puntkomma). Door het omsluiten van de tekst met het aanhalingsteken weten we dat de puntkomma als onderdeel van de omschrijving moet worden beschouwd.
Beschrijving parameters
Omschrijving (optioneel)
Uitleg voor deze parameter vind u hier.
CSV bestand (verplicht)
Het CSV-bestand dat u wilt inlezen en welke moet worden omgezet naar de dataset.
Scheidingsteken tussen de waarden (verplicht)
Hier geeft u aan welk teken moet worden beschouwd als scheidingsteken (= delimiter) tussen de waarden van elke regel.
Voorbeeld
20134344;1401;1190.00;"Houten ledikant; 2 meter"
In bovenstaande regel is het scheidingsteken een puntkomma.
U kunt alleen 1 teken opgeven. Indien u niets opgeeft of meer dan 1 teken, zal er een fout worden gegenereerd.
Teken dat tekst omsluit (verplicht)
Hier geeft u aan welk teken wordt gebruikt voor het omsluiten van teksten in de regels.
Voorbeeld
20134344;1401;1190.00;"Houten ledikant; 2 meter"
In bovenstaande regel is het teken dat de tekst omsluit een aanhalingsteken.
U kunt alleen 1 teken opgeven. Indien u niets opgeeft of meer dan 1 teken, zal er een fout worden gegenereerd.
Kolomnamen bevinden zich in de eerste regel
Voor de aan te maken dataset is het van belang dat aan elke kolom een naam wordt toegekend.
Vink deze optie aan indien in het CSV-bestand op de eerste regel kolomnamen zijn opgegeven.
Indien u deze kolomnamen ook wilt gebruiken voor de kolomnamen in de resulterende dataset, dan vult u niets in bij de parameter Te gebruiken kolomnamen.
Indien u deze kolomnamen niet wilt gebruiken voor de kolomnamen in de resulterende dataset, dan is het van belang dat u deze optie wel aanvinkt, anders zal de actie de eerste regel ook als een regel beschouwen waarin waarden staan, terwijl dit geen waarden maar kolomnamen zijn. Indien u in plaats van de kolomnamen op de eerste regel andere, zelf te specificeren, kolomnamen wilt gebruiken, dan kunt u deze opgeven bij de parameter Te gebruiken kolomnamen.
Te gebruiken kolomnamen
Voor de aan te maken dataset is het van belang dat aan elke kolom een naam wordt toegekend.
De hier opgegeven kolomnamen zullen voor de dataset worden gebruikt, ongeacht of de eerste regel van het CSV-bestand al kolomnamen bevat. Indien u hier niets opgeeft, is het van belang dat het CSV-bestand de kolomnamen bevat en dat u dit heeft aangegeven via het aanzetten van de parameter Kolomnamen bevinden zich in de eerste regel.
De kolomnamen voert u in, gescheiden met een puntkomma, zoals bijvoorbeeld:
FactuurNr;DebiteurNr;Bedrag;Omschrijving
Plaats resultaat in in dit geheugenveld
Dit is het geheugenveld van het type dataset, waarin u het resultaat wilt laten zetten.
Actie bij fout
Uitleg voor deze parameter vind u hier.